Published April 3, 2026
Why LLMs Are Not Deterministic Even at Temperature 0
5 min read

Kunpeng GUO
CTO
Have questions or want a demo?
We're here to help! Click the button below and we'll be in touch.
Get a Demo
AI Summary by QAnswer
By Kunpeng Guo
Introduction
A widespread assumption in the AI community is that setting temperature = 0 makes a Large Language Model (LLM) call fully reproducible — run the same prompt twice, get the same answer. In practice, this is almost never true. The variability may be subtle or dramatic depending on the model, the infrastructure, and the type of prompt — but it is there.
At QAnswer, we ran a structured benchmark to quantify this. We sent the same prompt ten times to the same model at temperature 0 and measured how often consecutive responses were byte-for-byte identical. The results are striking.
Benchmark Results
We tested five models across three different prompts. Each model received 10 paired runs at temperature 0 (except GPT-5, which was tested at temperature 1 as a deliberate control). Here are the results:
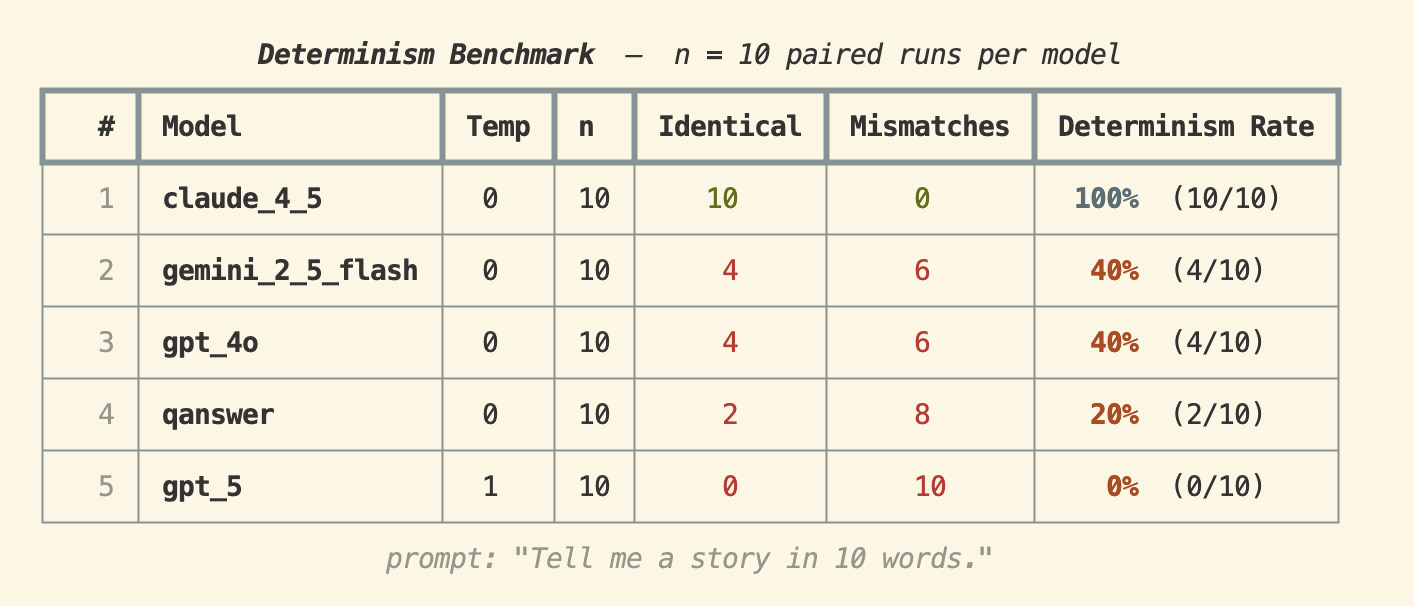
Prompt: "Tell me a story in 10 words."
Claude 4.5 achieved a 100% determinism rate — all 10 runs produced identical output. GPT-4o and Gemini 2.5 Flash both came in at 40%, while QAnswer scored 20%. GPT-5 (at temperature 1) had 0% — unsurprisingly, since high temperature is explicitly designed to introduce randomness.
Prompt: "Hello, who are you?"
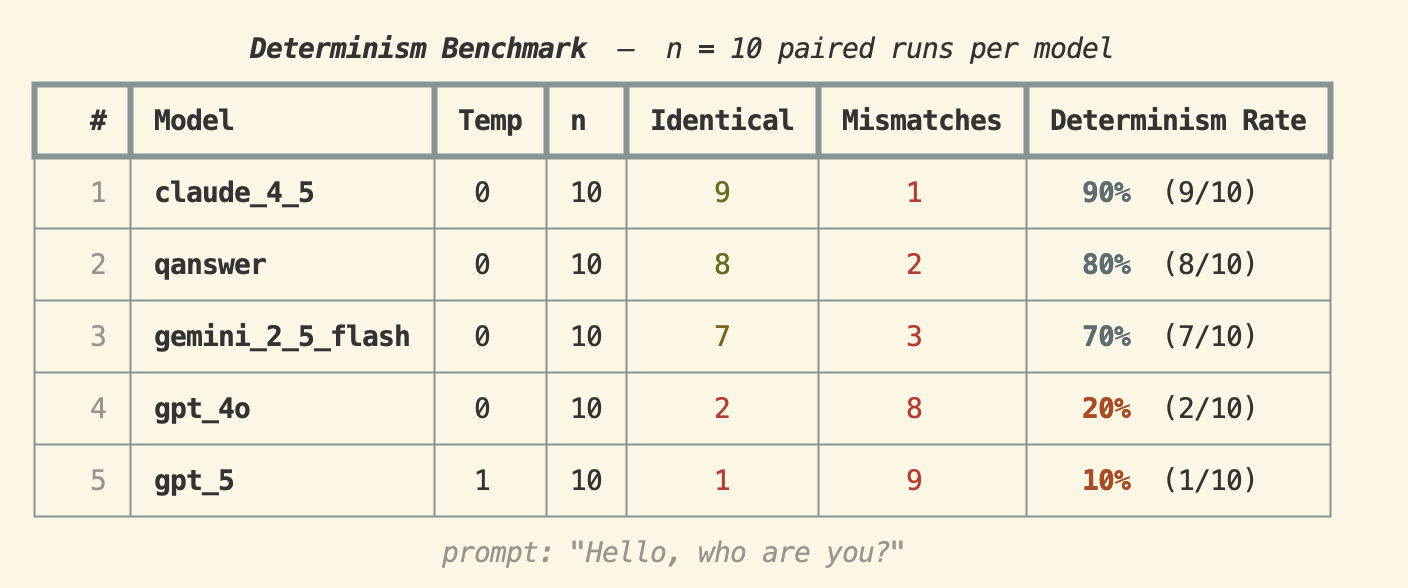
Claude 4.5 dropped to 90%, and interestingly QAnswer jumped to 80% — second place. Gemini 2.5 Flash achieved 70%, while GPT-4o fell sharply to 20%. GPT-5 scored 10% even at temperature 1, suggesting some minimal structural consistency.
Prompt: "Explain me prime numbers like I am a 5 year old."
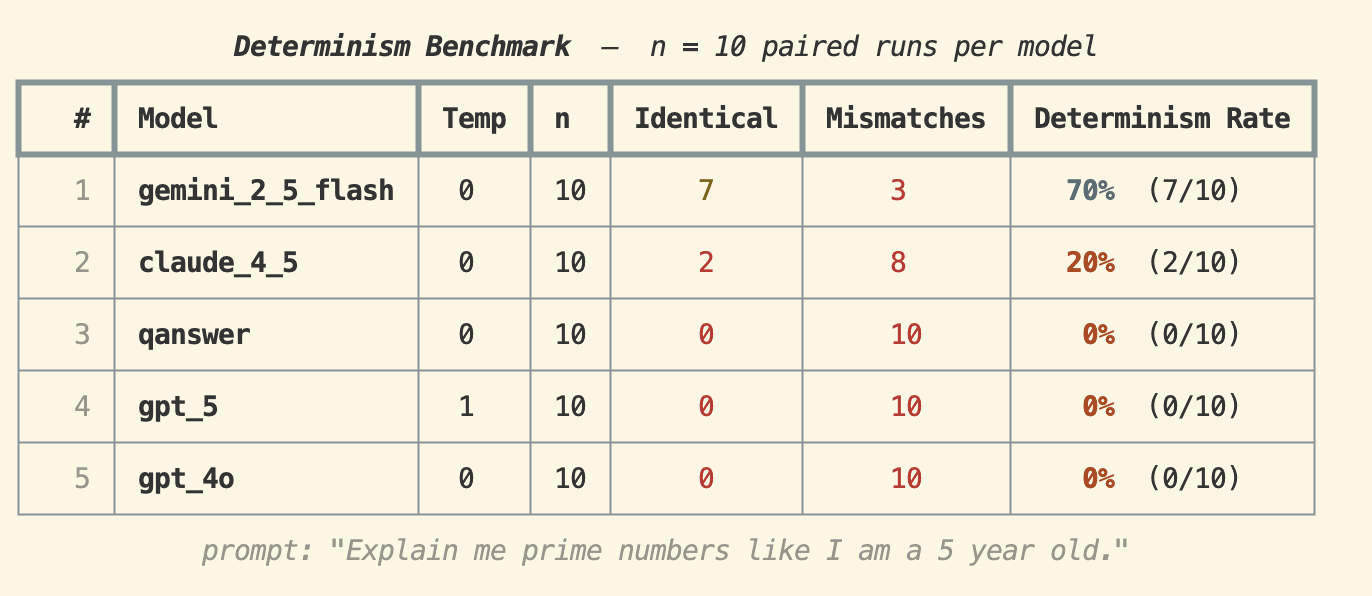
This longer, open-ended prompt reveals how quickly determinism collapses. Gemini 2.5 Flash led with 70%, Claude 4.5 fell to 20%, and QAnswer, GPT-5, and GPT-4o all scored 0%. When the prompt requires more tokens and more creative reasoning, reproducibility is essentially gone — even at temperature 0.
Why Does This Happen? Six Root Causes
The benchmark results are not a bug — they reflect fundamental properties of how modern LLMs are built and deployed. Here are the six main reasons:
1. Floating-Point Precision Limitations
Computers represent real numbers using floating-point formats with finite precision. During the billions of arithmetic operations inside a forward pass, tiny rounding errors accumulate and can cascade through subsequent token predictions. Even a difference of a single bit in an intermediate activation can flip the top-1 token when two candidates are nearly tied in probability.
2. Parallelism and Hardware Variability
LLMs execute on GPUs or TPUs that perform thousands of operations simultaneously. Floating-point addition is not perfectly associative — (a + b) + c can differ from a + (b + c) in floating-point arithmetic when rounding is involved. Different scheduling of parallel threads, or running the same model on different GPU architectures (e.g., A100 vs. H100 vs. T4), can produce subtly different sums and therefore different token probabilities.
3. Decoding Tie-Breaking
Temperature 0 means the model always selects the most probable next token — but what happens when two tokens have nearly identical probabilities? The tie-breaking rule may not be consistent across requests, and sampling parameters like top_k or top_p may still be active in some implementations, quietly reintroducing stochasticity even when temperature is set to zero.
4. Mixture-of-Experts (MoE) Architectures
Many state-of-the-art models (including some versions of GPT-4 and Gemini) use Mixture-of-Experts layers, where a router sends each token to one or more specialized sub-networks. In batched inference — where your query is processed alongside other users' requests — tokens from different sequences compete for the same expert slots. The routing decision for your token can therefore depend on what else is in the batch, introducing request-level variability that is entirely outside your control.
5. Non-Deterministic Framework Operations
Deep learning frameworks like PyTorch and TensorFlow optimize for speed, not reproducibility. Operations such as parallel reductions, atomics on GPU shared memory, and CUDA kernel launches may execute in a different order across runs. Unless the framework is explicitly configured for full determinism (which typically imposes a significant performance penalty), these operations introduce run-to-run variation at the hardware level.
6. Deployment and Infrastructure Factors
Cloud-hosted LLM APIs route requests across clusters of machines that may differ in hardware generation, driver versions, or model checkpoint versions. Load balancing means your two identical requests may land on different physical servers. Batching strategies — which group concurrent requests together to maximize GPU utilization — mean the exact composition of the batch changes with system load, directly affecting outputs for MoE models and indirectly affecting others through floating-point summation order.
What Does This Mean in Practice?
For most conversational applications, slight output variation at temperature 0 is acceptable — the semantic content of the answer is usually stable even when exact wording differs. However, for use cases that require strict reproducibility — automated pipelines, audit trails, compliance workflows, or deterministic test suites — temperature 0 alone is not sufficient.
If your application genuinely requires reproducible outputs, you need to:
- Cache responses and serve the cached result for repeated identical queries
- Use a self-hosted model on fixed hardware with full control over batch composition and framework determinism settings
- Design your downstream logic to be robust to minor output variation rather than assuming exact repeatability
Conclusion
Temperature 0 is a useful heuristic for making LLM outputs more consistent, but it is not a guarantee of determinism. Our benchmarks show that real-world determinism rates vary widely — from 100% on short, constrained prompts to 0% on longer, open-ended ones — and differ significantly across models and deployments.
Understanding this is essential for anyone building reliable AI-powered applications. At QAnswer, we design our platform with these constraints in mind, giving enterprises the control and transparency they need to deploy AI responsibly.
Interested in how QAnswer handles consistency and traceability in enterprise AI deployments? Try QAnswer for free or reach out at info@the-qa-company.com.
Back to Blog
The AI platform that works.
Try for free today
